Luciano Martins <lmartins@cpqd.com.br>
Diretoria de Redes e Telecomunicações - Gerência de Inovação em Redes
Fundação CPqD - Centro de Pesquisa e Desenvolvimento em Telecomunicações
Resumo
1. Introdução
2. OSPF com suporte a IPv6
2.1 Experimento com OSPF com suporte a IPv6
3. BGP com suporte a IPv6
3.1 Experimentos com BGP com suporte a IPv6
4. Considerações Finais
Referências bibliográficas
Resumo
Este artigo pretende abordar alguns conceitos sobre os protocolos de roteamento IPv6 OSPFv3 e BGP4+, bem como mostrar alguns resultados de experimentos realizados em um ambiente com sistemas Linux (Red Hat 7.3, Conectiva 7.0 e Conectiva 8.0) e FreeBSD 4.4, usando o software de roteamento gratuito Zebra, em sua última versão (zebra-0.92a). O artigo incluirá alguns trechos de configuração dos protocolos de roteamento das máquinas roteadoras e configuração do IPv6 nos sistemas Linux e FreeBSD, bem como as tabelas de roteamento resultantes.
1. Introdução
O protocolo IPv6 é um assunto vislumbrado por diversas instituições de pesquisa e, até mesmo, comerciais. A Fundação Centro de Pesquisa e Desenvolvimento em Telecomunicações (CPqD), possui um sub-projeto "IPv6 - IP de nova geração" dentro de uma pesquisa aplicada "NGN - Next Generation Network", que realiza, além da pesquisa em IPv6, estudos e aplicações práticas em diversas áreas, como qualidade de serviço, planejamento de redes, gerência e redes sem fio [1][2].
Segundo o Internet Software Consortium (ISC), existem atualmente mais de 147 milhões de hosts na Internet com um nome associado, tendo um crescimento médio de 20 milhões de hosts por ano [3]:
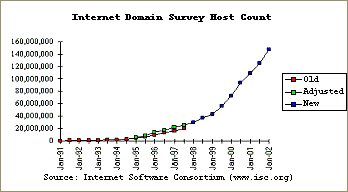
Figura 1 - Crescimento estatístico da Internet anualmente
Atualmente, existe certo consenso sobre o protocolo IP como a base para a convergência das redes de dados com as outras redes, incluindo-se voz e vídeo. O fator principal do sucesso do IP foi o fato do protocolo ser muito simples e, com isso, ser flexível o suficiente para se adaptar a diversos tipos de redes locais e de longa distância e, também, às aplicações de usuários.
Figura 2 - Convergência e previsão para o IPv6
O fator que mais encoraja a pesquisa e desenvolvimento sobre o protocolo IPv6 é o tamanho de seu endereçamento de 128 bits, contra 32 bits do atual IPv4. Os outros recursos do IPv6, tais como segurança em camada de rede fim-a-fim, qualidade de serviço melhorada, auto-configuração e outros, serão incrementos do protocolo para a melhoria dos serviços de rede.
Tendo o endereçamento do protocolo aumentado para 16 bytes, adaptações e até mesmo modificações estão sendo feitas, e outras serão necessárias, em protocolos de controle, de roteamento, em estruturas de registros de endereços [4] e outros.
O IPv6 é suportado por Interior Gateways Protocols (IGPs) e Exterior Gateway Protocols (EGPs). Exemplos de IPv6 IGPs são o RIPng (Routing Information Protocol - next generation) e o OSPFv3 (Open Shortest Path First - version 3). Um exemplo de EGP é o BGP4+ (Multiprotocol Border Gateway Protocol) [5].
O protocolo RIP, com IPv6, funciona como o RIP com IPv4 e oferece os mesmos benefícios. Os incrementos, para que o RIP trabalhe com IPv6, incluem suporte a endereços e prefixos IPv6 e o uso do endereço multicast "All RIP Routers" (ff02::9) como endereço de destino para mensagens RIP update. Os comandos para configuração em roteadores também foram modificados, como, por exemplo, no CISCO IOS CLI (Command-Line Interface) [5], e na interface do GNU ZEBRA [10].
Multiprotocol BGP para IPv6, ou BGP4+, funciona como o BGP para IPv4. Os incrementos para IPv6 incluem suporte à família IPv6 e atributos NLRI (Network Layer Reachability Information) e NEXT HOP. Ambos usam endereços IPv6 com diferentes escopos (global e link-local, por exemplo).
Este artigo pretende mostrar algumas modificações ocorridas nos protocolos OSPF e BGP para suportar IPv6, e algumas configurações e resultados de roteamento OSPF e BGP para IPv6, implementados em um ambiente IPv6 com o software GNU ZEBRA instalado em máquinas Linux e FreeBSD.
2. OSPF com suporte a IPv6
Nesta seção serão explanadas as principais modificações ocorridas no protocolo OSPF para suporte ao IPv6. Os detalhes podem ser encontrados na RFC 2740 [6].
O Open Shortest Path First (OSPF) é um protocolo do tipo link-state, usado no interior de um sistema autônomo (AS). Em um protocolo link-state, os roteadores trocam informações sobre os estados dos canais de comunicação (links) em que estão ligados.
Para melhor distribuir as tabelas de roteamento, o protocolo OSPF implementa o conceito de "Área". Uma rede pode ser dividida em diversas áreas. Cada área contém seus próprios roteadores e sua própria rede. Quando várias áreas são configuradas em uma mesmo AS, uma delas é chamada de backbone e o seu identificador é zero (área 0). O backbone é a área central e as outras áreas devem ser conectadas a ela através de roteadores, chamados de roteadores de borda de área (ABR). As informações de roteamento são enviadas para os roteadores no backbone, que propagam as informações para os roteadores nas bordas das áreas e assim por diante. Na figura a seguir, tem-se um exemplo de uma topologia OSPF dividida em áreas [7]:
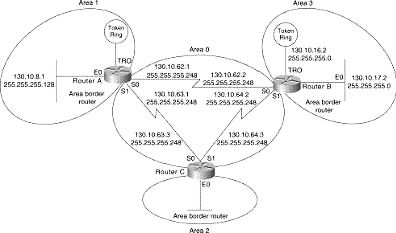
Figura 3 - Exemplo de áreas em uma topologia OSPF
Todas as áreas devem ter uma ligação com a área 0. Se isto não for possível, um canal de comunicação virtual (link virtual) é configurado. Este canal fornece um caminho lógico entre uma área e o backbone, e é estabelecido entre dois roteadores localizados nas fronteiras das áreas.
O OSPF utiliza uma entrega de atualizações (updates) ponto a ponto. Porém, quando há um domínio com suporte a broadcast, utiliza-o para agilizar a entrega das informações, elegendo-se um roteador mestre (DR - Designated Router) para que ele faça a distribuição de todas as atualizações.
O OSPF também permite o anúncio, para um AS, de rotas descobertas de outros AS´s externos, através da redistribuição de rotas de outros protocolos para o OSPF (por exemplo, BGP para OSPF).
Cada roteador OSPF armazena uma base de dados que descreve a topologia da rede e, a partir desta base, é construída a tabela de roteamento. É requerida uma certa quantidade de memória dos roteadores para o armazenamento da tabela de roteamento e da base de dados com as informações sobre os canais [8].
O roteador que participa do algoritmo SPF tem duas tarefas [9]:
- Testar ativamente o status de todos os roteadores próximos. Para efetuar status de teste o roteador troca mensagens curtas (Hello) para saber se os vizinhos estão ativos. Se ocorrer resposta dentro de um certo tempo esperado significa que o vizinho está ativo, caso contrário está inativo;
- Publicar periodicamente informações de estado do link (LSA´s - Link State Advertisements) para os demais roteadores. Para informar a todos roteadores, cada roteador difunde periodicamente uma mensagem que lista o status de cada um dos links.
Os roteadores OSPF se comunicam através de protocolos implementados acima do IP chamados de Hello, Exchange e Flooding. O Hello é responsável por verificar se os canais de comunicação estão operacionais. O Exchange é responsável pela sincronização inicial das bases de dados. O Flooding é responsável por manter as bases de dados sincronizadas. As mensagens geradas por um roteador podem informar [8]:
- os estados e os custos dos canais de comunicação aos quais o roteador encontra-se conectado;
- as redes que fazem parte do AS, mas que estão fora da área;
- os destinos externos aos AS´s ou uma rota default para fora do AS;
- os roteadores ligados por um segmento.
Em relação ao protocolo IPv6, os mecanismos fundamentais do OSPF, tais como flooding, DR election, area support, SPF calculation, e outros, não foram modificados. Porém, algumas mudanças foram necessárias para suportar a diferença semântica entre IPv4 e IPv6 e para suportar endereços de 128 bits. Algumas das principais diferenças técnicas são:
-
OSPF em IPv6 roda "por link", e não mais "por sub-rede";
O IPv6 usa o termo "link" para indicar um meio sobre o qual os nós podem se comunicar na camada de enlace. As interfaces conectam os links e múltiplos IPs de diferentes sub-redes podem ser associados a um link. Na especificação do OSPF para IPv4, usava-se o termo "rede" (network) e "sub-rede" (subnet) para a configuração do protocolo, o que no IPv6 será substituído pelo termo "enlace" (link).
-
Remoção das informações de endereçamento
As informações de endereçamento foram removidas dos pacotes OSPF e dos principais tipos de LSA´s, deixando o core independente de protocolo de rede:
- Endereços IPv6 não são mais apresentados em pacotes OSPF, exceto em payloads de LSA´s carregados por pacotes Link State Update;
- Router-LSA´s e Network-LSA´s não contêm mais endereços de rede;
- OSPF Router ID´s, Area ID´s e LSA Link State ID´s permanecem com 32 bits, ou seja, o endereço IPv4;
- Roteadores vizinhos são, agora, sempre identificados pelo Router ID, sendo que no IPv4 eram identificados pelo endereço IP da rede broadcast ou NBMA.
-
Adição de escopo para flooding
O escopo para o flooding de LSA´s é explicitamente codificado no campo LS TYPE dos LSA´s. Existem três escopos de flooding:
- Escopo link-local: o LSA é enviado somente no link entre dois roteadores. É usado para o novo formato do Link LSA;
- Escopo de área: LSA é enviado através de uma única área OSPF. Usado pelos Router-LSA´s, Network-LSA´s, Inter-Area-Prefix-LSA´s e Intra-Area-Prefix-LSA´s;
- Escopo de sistema autônomo (AS): LSA é enviado por todo o domínio de roteamento. Usado pelos AS-external-LSA´s
-
Suporte explícito a múltiplas instâncias por link
O OSPF para IPv6 suporta a habilidade de executar múltiplas instâncias do protocolo OSPF em um único link como, por exemplo, em um segmento de um ponto de troca de tráfego (PTT) compartilhado entre diversos provedores. Provedores podem estar executando domínios de roteamento separados, e querem mantê-los separados, mesmo tendo segmentos físicos em comum.
Com o IPv4, esta funcionalidade era suportada de forma casual, usando os campos de autenticação do header OSPF para IPv4. No IPv6, existe uma Instance ID, contida no header do pacote OSPF e estruturas de interface OSPF.
Outra aplicação para múltiplas instâncias é a de um link pertencer a duas ou mais áreas OSPF, simultaneamente.
-
Uso de endereços link-local
Os endereços link-local do IPv6 (fe80/10) não podem ser anunciados por roteadores e têm propósito de autoconfiguração, descobrimento de vizinhança e outros.
OSPF para IPv6 assume que cada roteador tem associado em cada uma de suas interfaces um endereço link-local. Em todas as interfaces, exceto links virtuais, pacotes OSPF são enviados usando como origem o endereço link-local associado à interface. Um roteador aprende os endereços link-local de todos os roteadores conectados a seus links, e usa esses endereços como informação de próximo hop durante o encaminhamento de pacotes.
Em links virtuais, endereços de escopo global e de escopo de site devem ser utilizados como origem dos pacotes OSPF. Endereços link-local aparecem apenas em Link-LSA´s, não sendo permitido em outros tipos de LSA´s, como Inter-area-prefix-LSA, AS-external-LSA ou Intra-area-prefix-LSA´s.
-
Mudanças na autenticação
No OSPF para IPv6, a autenticação foi removida do protocolo OSPF. Os campos AUTYPE e AUTHENTICATION foram removidos do header do pacote OSPF, e todos os campos relacionados com autenticação foram removidos das estruturas de interface e área do OSPF.
Com o IPv6, o OSPF conta com o Authentication Header (AH) e Encapsulationg Security Payload (ESP) para certificar a integridade e confidencialidade das trocas de roteamento.
-
Mudanças no formato de pacote
As mudanças no formato do pacote OSPF consistem de:
- O número da versão do OSPF foi alterado de 2 para 3;
- O campo OPTIONS no pacote Hello e no pacote Database Description foi expandido para 24 bits;
- Os campos AUTHENTICATION e AUTYPE foram removidos do header do pacote do OSPF;
- O pacote Hello não contém informações de endereçamento e inclui uma INTERFACE ID que o roteador de origem atribui para identificar unicamente sua interface para o link. Esta INTERFACE ID se torna o LINK-STATE ID dos Network-LSA´s, no caso do roteador se tornar o Designated Router (DR) no link;
- Dois bits opcionais, o bit "R" e o bit "V6", foram acrescentados no campo OPTIONS para o processamento de Router-LSA´s durante o cálculo do algoritmo SPF (Shortest Path First). Se o bit R está zerado, o roteador OSPF pode participar da distribuição de topologia OSPF sem ser usado para encaminhar trafego de trânsito. Isto pode ser usado em hosts multihomed que queiram participar do protocolo de roteamento. O bit "V6" especializa o bit "R". Se o bit "V6" está zerado, o roteador OSPF pode participar da distribuição de topologia OSPF sem ser usado para encaminhar datagramas IPv6. Se o bit "R" estiver setado e o bit "V6" zerado, datagramas IPv6 não são encaminhados, mas os datagramas relacionados a outras famílias de protocolos podem ser transferidos.
- O header do pacote OSPF agora inclui uma INSTANCE ID que permite que múltiplas instâncias do protocolo rodem sobre um único link.
-
Mudanças no formato do LSA
Todas as informações de endereçamento foram removidas do header do LSA e dos Router-LSA´s e Network-LSA´s. Estes dois tipos de LSA´s agora descrevem a topologia do roteamento do domínio de uma maneira independente de protocolo de rede.
Novos LSA´s foram adicionados para distribuir informações de endereços IPv6 e dados necessários para a resolução de próximo hop. Os nomes de algumas LSA´s do IPv4 foram mudadas para serem mais consistentes umas com as outras.
Em detalhes, as alterações no formato do LSA são:
- O campo OPTIONS foi removido do header LSA, expandido para 24 bits, e movido para o corpo dos Router-LSA´s, Inter-Area-Router-LSA´s e Link-LSA´s;
- O campo LSA TYPE foi expandido para 16 bits, com os 3 bits superiores codificando o escopo do flooding e de tratamento de tipos de LSA desconhecidos;
- Os endereços nos LSA´s agora são expressos como [prefix,prefix length] ao invés de [address, mask] do IPv4. A rota default é expressa com um prefixo de comprimento 0;
- Os Router-LSA´s e Network-LSA´s agora não têm informações de endereços, e são independentes de protocolo de rede;
- Informações sobre as interfaces do roteador podem ser emitidas através de múltiplos Router-LSA´s. Os receptores devem concatenar todos os Routers-LSA´s originados por um roteador quando for executar o cálculo de SPF;
- Foi introduzido um novo LSA, chamado Link-LSA, que tem o escopo link-local para o flooding (nunca irá além do link a que está associado). Este LSA tem 3 propósitos:
- Fornece os endereços link-local do roteador para todos os outros roteadores conectados a ele no link;
- Informa aos roteadores conectados vizinhos a lista de prefixos IPv6 associados com o link;
- Permite que o roteador declare uma coleção de Option bits a ser associado com o Network-LSA que será originada para o link.
No IPv4, o Router-LSA carrega os endereços das interfaces IPv4 do roteador, equivalentes aos endereços link-local no IPv6. Estes somente são usados para calcular próximos hops durante o cálculo do roteamento OSPF. Portanto, não necessitam ser encaminhados para fora do link local. Por isso, usar Link-LSA´s para distribuir estes endereços é mais eficiente.
- Os Type 3 summary-LSA´s foram renomeados para Inter-Area-Prefix-LSA´s e os Type 4 summary-LSA´s foram renomeados para Inter-Area-Router-LSA´s;
- O Link State ID nos Inter-Area-Prefix-LSA´s, Inter-Area-Router-LSA´s e AS-external-LSA´s perdeu sua semântica de endereçamento, e agora serve somente para identificar partes individuais da Link State Database. Todos os endereços ou Router ID´s, que eram anteriormente expressos pelo Link State ID, agora são carregados nos corpos do LSA;
- Um Network-LSA deve listar todos os roteadores conectados no link e um Link-LSA deve listar todos os endereços de roteadores no link;
- Um novo LSA chamado Intra-Area-Prefix-LSA foi criado. Este LSA carrega toda a informação de prefixos IPv6 que no IPv4 era incluída em Router-LSA´s e Network LSA´s.
-
Tratamento de tipos de LSA desconhecidos
O comportamento do OSPF para IPv4, de simplesmente descartar tipos desconhecidos, não é mais suportado.
O tratamento de tipos de LSA´s desconhecidos agora é mais flexível de forma que, baseando-se no tipo de LSA (LS Type), tipos desconhecidos são tratados como tendo escopo link-local de flooding, ou são armazenados e inundados como se fossem conhecidos. Este comportamento é explicitamente codificado no bit LSA Handling do campo LS TYPE do header link state.
-
Suporte a Stub Area
No OSPF para IPv4, as stub areas foram projetadas para minimizar o tamanho da base de dados OSPF (link state database) e o tamanho das tabelas de roteamento para roteadores internos às áreas. Isto permite que roteadores com recursos mínimos participem em domínios de roteamento OSPF muito grandes.
No OSPF para IPv6, o conceito de stub areas foi mantido. No IPv6, as stub areas carregam apenas Router-LSA´s, Network-LSA´s e Inter-Area-Prefix-LSA´s. Estes são os equivalentes IPv6 aos tipos de LSA´s carregados em stub areas IPv4: Router-LSA´s, Network-LSA´s e Type 3 summary-LSA´s.
Além disso, de maneira diferente do IPv4, o IPv6 permite que LSA´s com LS TYPE desconhecidos sejam rotulados como "Armazene e inunde o LSA como se o tipo fosse conhecido" (Store and flood the LSA, as if type understood). Porém, seu uso é controlado verificando-se o escopo.
-
Identificação de vizinhos pelo Router IDs
No OSPF para IPv6, roteadores vizinhos em um dado link sempre serão identificados pelo seu Router ID. Isto contrasta com o comportamento do IPv4, onde os vizinhos numa rede ponto-a-ponto e nos links virtuais são identificados pelos seus Router ID´s e vizinhos em redes broadcast, NBMA e ponto-multiponto são identificados pelos seus próprios endereços de interface IPv4.
Após dadas as principais modificações técnicas ocorridas no OSPF para suporte ao IPv6, será mostrada um experiência prática com este protocolo.
2.1 Experimento com OSPF com suporte a IPv6
A fim de realizar testes básicos com o protocolo OSPF para IPv6, configurou-se um ambiente com máquinas Linux Red Hat 7.3, Linux Conectiva 7 e 8 e FreeBSD 4.4. Todos estes sistemas operacionais possuem suporte ao protocolo IPv6.
Em cada um destes sistemas foi instalado o software "zebra-0.92a" [10], que é um software livre gerenciador de protocolos de roteamento baseados na pilha TCP/IP. Este software suporta protocolos como BGP-4, RIPv1, RIPv2, RIPng, OSPFv2 e OSPFv3.
Para a instalação do zebra no sistema, fez-se o download do software, e em seguida, foi instalado de acordo com o seguinte procedimento:
modprobe ipv6
tar xvfz /usr/src/zebra0.92a.tar.gz
cd /usr/src/zebra0.92a
./configure
make
make install
make clean
Esses comandos criam em /usr/sbin os programas "zebra", "ospfd", "ospf6d", "ripd", "ripngd" e "bgpd". Para que os protocolos de roteamento com suporte a IPv6 sejam instalados, é necessário inserir o módulo "ipv6" antes da compilação do software.
A figura 4 ilustra a topologia de teste realizada. Foram usados endereços IPv6 com escopo "site-local" (fec0) simplificados. Em um ambiente real para conexão a redes IPv6, como, por exemplo, ao 6Bone ou ao projeto piloto de IPv6 do Brasil [2], endereços de escopo global deveriam ser configurados.
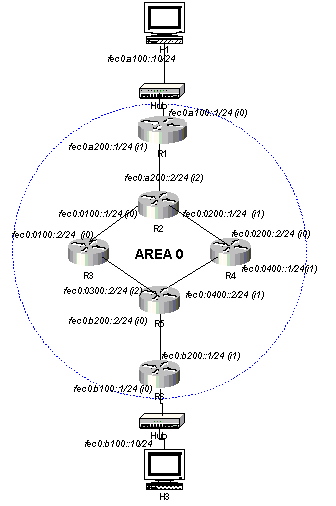
Figura 4 - Topologia de teste para o protocolo OSPF para IPv6
Para exemplificar a configuração e os resultados nesta topologia, serão mostradas as configurações do roteador R2 (Linux).
Inicialmente, a configuração das interfaces e a inicialização dos daemons "zebra" e "ospf6d" é necessária, para que o protocolo OSPF para IPv6 possa ser executado satisfatoriamente.
ifconfig eth2 inet6 add fec0:a200::2/24
ifconfig eth1 inet6 add fec0:0200::1/24
ifconfig eth0 inet6 add fec0:0100::1/24
/usr/local/sbin/zebra -d
/usr/local/sbin/ospf6d -d
Na inicialização do daemon ospf6d, o arquivo de configuração do OSPF para IPv6, o"ospf6d.conf", localizado no diretório /usr/local/etc do sistema, é procurado.
No caso do roteador R2, este arquivo tem o seguinte formato:
hostname R2
password ********
log stdout
router ospf6
router-id 2.2.2.2
interface eth0 area 0.0.0.0
interface eth1 area 0.0.0.0
interface eth2 area 0.0.0.0
Como foi comentado anteriormente na parte teórica sobre OSPF, o ROUTER ID permanece sendo de 32 bits, e o processo OSPF é executado "por interface" (interface) e não mais "por sub-rede" (network). Todos os roteadores estão na área "0" (0.0.0.0). Nesta versão do zebra, ainda não há implementação de suporte a áreas no IPv6.
Após configurados devidamente todos os roteadores, a tabela de roteamento OSPF de R2 fica da seguinte forma:
| Destination | Options Area Cost | Type2 IS | Origin | Nexthop | I/F |
| *IA fec0:100::/24 | V6E---R-- 0.0.0.0 | 1 0 | 3.3.3.3[2] | :: | eth0 |
| *IA fec0:200::/24 | V6E---R-- 0.0.0.0 | 1 0 | 2.2.2.2[3] | :: | eth1 |
| *IA fec0:300::/24 | V6E---R-- 0.0.0.0 | 2 0 | 5.5.5.5[3] | fe80::260:8ff:fe2b:4d22 | eth0 |
| *IA fec0:400::/24 | V6E---R-- 0.0.0.0 | 2 0 | 5.5.5.5[2] | fe80::200:f8ff:fe04:370 | eth0 |
| *IA fec0:a100::/24 | V6E---R-- 0.0.0.0 | 2 0 | 1.1.1.1[0] | fe80::220:afff:fe9b:feed | eth2 |
| *IA fec0:a200::/24 | V6E---R-- 0.0.0.0 | 1 0 | 1.1.1.1[2] | :: | eth2 |
| *IA fec0:b100::/24 | V6E---R-- 0.0.0.0 | 4 0 | 6.6.6.6[0] | fe80::200:f8ff:fe04:3704 | eth1 |
| *IA fec0:b100::/24 | V6E---R-- 0.0.0.0 | 4 0 | 6.6.6.6[0] | fe80::260:8ff:fe2b:4d22 | eth0 |
| *IA fec0:b200::/24 | V6E---R-- 0.0.0.0 | 3 0 | 5.5.5.5[1] | fe80::200:f8ff:fe04:3704 | eth1 |
| *IA fec0:b200::/24 | V6E---R-- 0.0.0.0 | 3 0 | 5.5.5.5[1] | fe80::260:8ff:fe2b:4d22 | eth0 |
Esta tabela mostra o next-hop para cada um dos destinos, sendo o endereço link-local dos roteadores vizinhos que anunciaram o prefixo de destino para o roteador R2. Informações sobre as opções, área e Router ID do anunciante da rota também podem ser verificadas nesta tabela. O símbolo "::" indica que o responsável pela rota é o próprio roteador R2.
Estas rotas foram refletidas para a tabela de roteamento IP do kernel, como pode ser visto a seguir:
| Kernel IPv6 routing table | |||||
| Destination | Next Hop | Flags | Metric | Ref | Use Iface |
| ::1/128 | :: | U | 0 | 12 | 0 lo |
| fe80::200:f8ff:fe04:3704/128 | fe80::200:f8ff:fe04:3704 | UAC | 0 | 8 | 0 eth1 |
| fe80::206:5bff:fe28:ab5e/128 | :: | U | 0 | 69986 | 0 lo |
| fe80::220:afff:fe9b:feed/128 | fe80::220:afff:fe9b:feed | UAC | 0 | 63 | 1 eth2 |
| fe80::260:8ff:fe2b:4b33/128 | :: | U | 0 | 21243 | 0 lo |
| fe80::260:8ff:fe2b:4d22/128 | fe80::260:8ff:fe2b:4d22 | UAC | 0 | 8 | 0 eth0 |
| fe80::260:8ff:fe3e:f338/128 | :: | U | 0 | 72517 | 0 lo |
| fe80::/10 | :: | UA | 256 | 0 | 0 eth1 |
| fe80::/10 | :: | UA | 256 | 0 | 0 eth2 |
| fe80::/10 | :: | UA | 256 | 0 | 0 eth0 |
| fec0:100::1/128 | :: | U | 0 | 168 | 0 lo |
| fec0:100::/24 | :: | UA | 256 | 0 | 0 eth0 |
| fec0:200::1/128 | :: | U | 0 | 8 | 0 lo |
| fec0:200::/24 | :: | UA | 256 | 0 | 0 eth1 |
| fec0:300::/24 | fe80::260:8ff:fe2b:4d22 | UG | 1024 | 15 | 1 eth0 |
| fec0:400::/24 | fe80::200:f8ff:fe04:3704 | UG | 1024 | 0 | 0 eth1 |
| fec0:a100::/24 | fe80::220:afff:fe9b:feed | UG | 1024 | 24 | 0 eth2 |
| fec0:a200::2/128 | :: | U | 0 | 5 | 0 lo |
| fec0:a200::/24 | :: | UA | 256 | 0 | 0 eth2 |
| fec0:b100::/24 | fe80::260:8ff:fe2b:4d22 | UG | 1024 | 3 | 1 eth0 |
| fec0:b200::/24 | fe80::260:8ff:fe2b:4d22 | UG | 1024 | 0 | 0 eth0 |
| ff02::5/128 | ff02::5 | UAC | 0 | 4 | 0 eth1 |
| ff02::5/128 | ff02::5 | UAC | 0 | 4 | 0 eth0 |
| ff02::5/128 | ff02::5 | UAC | 0 | 4 | 0 eth2 |
| ff02::1:ff00:1/128 | ff02::1:ff00:1 | UAC | 0 | 1 | 0 eth0 |
| ff00::/8 | :: | UA | 256 | 0 | 0 eth1 |
| ff00::/8 | :: | UA | 256 | 0 | 0 eth2 |
| ff00::/8 | :: | UA | 256 | 0 | 0 eth0 |
A configuração e resultados para todos os roteadores são similares ao roteador R2. Os hosts devem ter seu gateway default configurado para o endereço IPv6 da interface do roteador que se encontra no link entre host e roteador.
Agora, veremos alguns conceitos sobre IPv6 no BGP (BGP4+) e, logo após, será mostrado o teste realizado com este protocolo.
3. BGP com suporte a IPv6
Conforme relatado na RFC 2545 [11], o BGP é um protocolo de path vector, usado para transportar informações de roteamento entre sistemas autônomos. O termo path vector vem do fato de que as informações de roteamento BGP transportam uma seqüência de números de AS´s e os prefixos de rede, que identificam o caminho dos AS´s para a informação atravessar. As informações do caminho, associadas com o prefixo, são usadas para prevenir loops.
O BGP usa o TCP como protocolo de transporte (porta 179). Isto assegura que, todo o transporte das informações seja confiável.
Os roteadores que utilizam o protocolo BGP são chamados BGP speakers. Dois BGP speakers (peers ou vizinhos) estabelecem uma conexão TCP entre eles (sessão), com o propósito de trocarem informações de roteamento, conforme exemplificado na figura 5 [12]:
Figura 5 - Roteadores BGP estabelecendo vizinhança
O protocolo BGP, sem extensão, é capaz de carregar apenas informações de roteamento para o protocolo IPv4. Extensões deste protocolo para múltiplos protocolos de camada de rede possibilitam que o protocolo IPv6 seja, agora, suportado por BGP. Esta extensão para IPv6 é chamada de BGP4+ e, para multicast, MBGP [13].
As únicas partes de informação carregadas pelo BGP-4, que são específicas ao IPv4, são:
- atributo NEXT_HOP, expresso como um endereço IPv4;
- AGGREGATOR, contendo um endereço IPv4;
- NLRI (Network Layer Reachability Information), expresso como prefixos de endereço IPv4.
Para possibilitar que BGP-4 suporte roteamento para múltiplos protocolos de camada de rede, deve-se adicionar:
- a habilidade de associar um endereço de rede particular para o atributo NEXT-HOP;
- a habilidade de associar um particular protocolo de camada de rede com a NLRI.
Dois novos atributos foram inseridos na extensão para o protocolo BGP, segundo a RFC 2858, para que múltiplos protocolos de rede pudessem ser difundidos:
- o Multiprotocol Reachable NLRI (MP_REACH_NLRI): usado para carregar o conjunto de destinos alcançáveis junto com informações de next-hop que serão usadas para encaminhamento para estes destinos;
- o Multiprotocol Unreachable NLRI (MP_UNREACH_NLRI): usado para carregar o conjunto de destinos inalcançáveis.
Estes atributos são opcionais e, no caso de um BGP speaker não suportar multiprotocolo, este ignorará estas informações e não passará para seus peers. Seus formatos podem ser encontrados na RFC 2858.
Em termos de informações de roteamento, a diferença mais significante entre o IPv6 e o IPv4 (para o qual o BGP foi projetado originalmente) é o fato de que, no IPv6, é introduzido o escopo de endereços unicast e definem-se situações particulares quando um escopo particular de endereço deve ser usado [11]. Veremos algumas regras necessárias para a acomodação de endereços IPv6 e seus escopos, relacionando com os atributos de extensão acima citados.
-
Escopos de Endereços IPv6
O IPv6 define três escopos de endereços unicast: global, site-local e link-local. Endereços site-local são endereços non-link-local válidos dentro do escopo de um site e não pode ser exportado além do mesmo. Os endereços globais e site-local são tratados da mesma forma e ambos são referidos como endereços "global" ou "non-link-local".
As especificações do IPv6 definem que somente endereços com escopo link-local podem ser usados em mensagens ICMP Redirect. Além disso, para alguns protocolos de roteamento, como RIPng, o next-hop também deve ser um endereço de escopo link-local. Estas restrições implicam que um roteador IPv6 deve ter um endereço link-local do próximo hop para todas as rotas conectadas diretamente a ele. Endereços link-local não são adequados para serem usados como atributos de next-hop no BGP-4.
Devido às razões acima apresentadas, quando o BGP-4 é usado para transportar informações de alcançabilidade IPv6 é, às vezes, necessário anunciar um atributo de next-hop que consiste de um endereço global e um endereço link-local.
O item seguinte descreve as regras que devem ser seguidas quando construir o campo Network Address of Next Hop do atributo de extensão MP_REACH_NLRI [11] .
-
Construção do campo NEXT HOP
Um BGP speaker publicará para a seu peer, no campo "Network Address of Next Hop", o endereço IPv6 global do próximo hop, seguido pelo endereço IPv6 link-local do próximo hop.
O valor do tamanho, no campo "Length of Next Hop Network Address", no atributo MP_REACH_NLRI, deve ser configurado para 16 (bytes), quando somente um endereço global estiver presente, ou 32, se o endereço link-local também estiver incluído no campo NEXT HOP.
O endereço link-local deverá ser incluído no campo NEXT HOP se, e somente se, o BGP speaker compartilhar uma sub-rede comum com a entidade, identificada por um endereço IPv6 global transmitido no campo "Network Address of Next Hop", e a rota estiver sendo publicada para o peer.
Em todos os outros casos, um BGP speaker publicará para os peers, neste mesmo campo, apenas o endereço IPv6 global.
-
Transporte
As conexões TCP, no topo da qual mensagens BGP-4 são trocadas, podem ser estabelecidas sobre IPv4 ou IPv6. Como o BGP-4 é independente do transporte particular usado, ele utiliza a informação de endereço configurado na interface para estabelecer uma sessão com seu peer (peering session). Esta informação (o endereço de rede de um peer) é levada em conta no procedimento da disseminação da rota.
Assim, quando se usa o TCP sobre IPv4 como transporte para a informação de alcançabilidade IPv6, é necessária uma configuração explícita adicional do endereço de rede do peer.
O uso do TCP sobre o IPv6, como protocolo de transporte para a informação de alcançabilidade IPv6, tem a vantagem de fornecer uma confirmação explicita da alcançabilidade da rede IPv6 entre dois pares .
3.1 Experimentos com BGP com suporte a IPv6
A fim de realizar testes básicos com o protocolo BGP para IPv6, configurou-se uma topologia com 4 sistemas autônomos, sendo que um deles (AS 100) possui configurado o protocolo OSPF para IPv6. A figura 6 ilustra a topologia de teste:
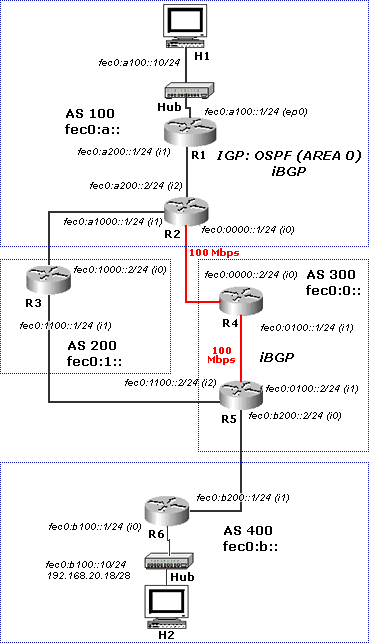
Figura 6 - Topologia de teste para BGP com IPv6
Nesta topologia, R1 executa apenas OSPF, e R3, R4, R5 e R6 executam apenas BGP. O roteador R2, sendo um roteador de borda entre AS´s (ASBR) e conversando com um roteador interno ao AS por OSPF e com um roteador externo ao AS por BGP, deve executar ambos os protocolos de roteamento. Ainda neste roteador, é necessária a redistribuição das rotas aprendidas por BGP para os OSPF e vice-versa, para que todas as rotas sejam aprendidas por todos os roteadores. Agregação de rotas não foi utilizada neste teste.
Serão mostrados a configuração do roteador R2 e os resultados das tabelas de roteamento. Inicialmente, a configuração das interfaces e a inicialização dos daemons "zebra", "ospf6d" e "bgpd" são necessárias:
ifconfig eth0 inet6 add fec0:0000::1/24
ifconfig eth1 inet6 add fec0:1000::1/24
ifconfig eth2 inet6 add fec0:a200::2/24
/usr/local/sbin/zebra -d
/usr/local/sbin/ospf6d -d
/usr/local/sbin/bgpd -d
Na inicialização do daemon ospf6d, como visto no experimento em 2.1, o arquivo de configuração do OSPF para IPv6 - ospf6d.conf -, fica no diretório /usr/local/etc do sistema. Já na inicialização do daemon bgpd, o arquivo bgpd.conf, no mesmo local, é procurado.
No caso do roteador R2, estes arquivos têm o seguinte formato:
OSPF6D.CONF
hostname R2
password ******
router ospf6
router-id 2.2.2.2
redistribute bgp
interface eth0 area 0.0.0.0
interface eth1 area 0.0.0.0
interface eth2 area 0.0.0.0
BGPD.CONF
hostname R2
password *******
router bgp 100
bgp router-id 2.2.2.2
ipv6 bgp redistribute ospf6
ipv6 bgp network fec0:a200::/24
ipv6 bgp neighbor fec0:0000::2 remote-as 300
ipv6 bgp neighbor fec0:1000::2 remote-as 200
Assim como no OSPF, o ROUTER ID do BGP permanece sendo de 32 bits. Tanto no OSPF quanto no BGP, foi necessária a redistribuição entre estes protocolos (redistribute). O comando network do BGP faz com que o roteador R2 anuncie esta rota por BGP, e os comandos neighbor indicam os peers e os AS´s aos quais os peers pertencem.
Após devidamente configurados todos os roteadores, as tabelas de roteamento OSPF e BGP de R2 ficam da seguinte forma:
| Tabela OSPF | |||||
| Destination | Options Area | Cost Type2 | LS Origin | Nexthop | I/F |
| *IA fec0:a100::/24 | V6E---R-- 0.0.0.0 | 2 0 | 1.1.1.1[0] | fe80::220:afff:fe9b:feed | eth2 |
| *IA fec0:a200::/24 | V6E---R-- 0.0.0.0 | 1 0 | 1.1.1.1[3] | :: | eth2 |
| Tabela BGP | |||
| BGP table version is 0, local Router ID is 2.2.2.2 | |||
| Status codes: s suppressed, d damped, h history, * valid, > best, i - internal | |||
| Origin codes: i - IGP, e - EGP, ? - incomplete | |||
| Network | Metric | LocPrf | Weight Path |
| * fec0::/24 fec0:1000::2(fe80::220:afff:fed2:bc2e) |
0 200 300 i | ||
|
*> fec0::/24 fec0::2(fe80::201:2ff:fe74:da90 |
0 300 i | ||
| * fec0:100::/24 fec0:1000::2(fe80::220:afff:fed2:bc2e) |
0 200 300 i | ||
|
*> fec0:100::/24 fec0::2(fe80::201:2ff:fe74:da90) |
0 300 i | ||
|
*> fec0:1000::/24 fec0:1000::2(fe80::220:afff:fed2:bc2e) |
0 200 i | ||
| * fec0:1000::/24 fec0::2(fe80::201:2ff:fe74:da90) |
0 300 200 i | ||
| * fec0:1100::/24 fec0:1000::2(fe80::220:afff:fed2:bc2e) |
0 200 i | ||
|
*> fec0:1100::/24 fec0::2(fe80::201:2ff:fe74:da90) |
0 300 i | ||
|
*> fec0:a100::/24 :: |
0 | 32768 ? | |
|
*> fec0:a200::/24 :: |
32768 i | ||
| * fec0:b100::/24 fec0:1000::2(fe80::220:afff:fed2:bc2e) |
0 200 300 400 i | ||
|
*> fec0:b100::/24 fec0::2(fe80::201:2ff:fe74:da90) |
0 300 400 i | ||
| * fec0:b200::/24 fec0:1000::2(fe80::220:afff:fed2:bc2e) |
0 200 300 400 i | ||
|
*> fec0:b200::/24 fec0::2(fe80::201:2ff:fe74:da90) |
0 300 400 i | ||
| Total number of prefixes 8 | |||
A tabela BGP mostra o next-hop, aprendidas tanto por endereços IPv6 site-local (non-link-local), quanto por endereços link-local, em concordância com o item 3b. As rotas com o símbolo ">" são as rotas preferidas, devido a ter um "peso" maior ou um "caminho" (número de AS´s) menor.
Estas rotas foram refletidas para a tabela de roteamento IP do kernel, como pode ser visto a seguir:
| Destination | Next Hop | Flags | Metric | Ref | Use Iface |
| ::1/128 | :: | U | 0 | 15 | 0 lo |
| fe80::203:47ff:fe23:570/128 | :: | U | 0 | 3 | 0 lo |
| fe80::206:5bff:fe28:ab5e/128 | :: | U | 0 | 20 | 0 lo |
| fe80::260:8ff:fe3e:f338/128 | :: | U | 0 | 0 | 0 lo |
| fe80::/10 | :: | UA | 256 | 0 | 0 eth0 |
| fe80::/10 | :: | UA | 256 | 0 | 0 eth1 |
| fe80::/10 | :: | UA | 256 | 0 | 0 eth2 |
| fec0::1/128 | :: | U | 0 | 55 | 0 lo |
| fec0::2/128 | fec0::2 | UAC | 0 | 1 | 1 eth0 |
| fec0::/24 | :: | UA | 256 | 0 | 0 eth0 |
| fec0:100::/24 | fe80::201:2ff:fe74:da90 | UG | 1024 | 0 | 0 eth0 |
| fec0:1000::1/128 | :: | U | 0 | 539 | 0 lo |
| fec0:1000::2/128 | fec0:1000::2 | UAC | 0 | 1 | 1 eth1 |
| fec0:1000::/24 | :: | UA | 256 | 0 | 0 eth1 |
| fec0:1100::/24 | fe80::201:2ff:fe74:da90 | UG | 1024 | 0 | 0 eth0 |
| fec0:a100::/24 | fe80::220:afff:fe9b:feed | UG | 1024 | 4 | 0 eth2 |
| fec0:a200::2/128 | :: | U | 0 | 195 | 0 lo |
| fec0:a200::/24 | :: | UA | 256 | 0 | 0 eth2 |
| fec0:b100::/24 | fe80::201:2ff:fe74:da90 | UG | 1024 | 204 | 1 eth0 |
| fec0:b200::/24 | fe80::201:2ff:fe74:da90 | UG | 1024 | 0 | 0 eth0 |
| ff02::5/128 | ff02::5 | UAC | 0 | 285 | 1 eth2 |
| ff02::5/128 | ff02::5 | UAC | 0 | 1 | 0 eth0 |
| ff02::5/128 | ff02::5 | UAC | 0 | 1 | 0 eth1 |
| ff00::/8 | :: | UA | 256 | 0 | 0 eth0 |
| ff00::/8 | :: | UA | 256 | 0 | 0 eth1 |
| ff00::/8 | :: | UA | 256 | 0 | 0 eth2 |
Em R1, onde está sendo executado apenas o protocolo OSPF, pode-se verificar que as rotas aprendidas pelo BGP em R2, que são de outros sistemas autônomos, e redistribuídas para R1 via OSPF, possuem a marcação "E1" na tabela, mostrada a seguir:
R1
| Destination | Options Area | Cost Type2 | LS Origin | Nexthop | I/F |
| *IA fec0::/24 | V6E---R-- 0.0.0.0 | 2 0 | 192.168.10.1[0] | fe80::206:5bff:fe28:ab5e | ep1 |
| *E1 fec0:100::/24 | V6E---R-- 0.0.0.0 | 101 0 | 192.168.10.1[1] | fe80::206:5bff:fe28:ab5e | ep1 |
| *IA fec0:1000::/24 | V6E---R-- 0.0.0.0 | 2 0 | 192.168.10.1[0] | fe80::206:5bff:fe28:ab5e | ep1 |
| *E1 fec0:1100::/24 | V6E---R-- 0.0.0.0 | 101 0 | 192.168.10.1[2] | fe80::206:5bff:fe28:ab5e | ep1 |
| *IA fec0:a200::/24 | V6E---R-- 0.0.0.0 | 1 0 | 192.168.10.17[3] | :: | ep1 |
| *E1 fec0:b100::/24 | V6E---R-- 0.0.0.0 | 101 0 | 192.168.10.1[3] | fe80::206:5bff:fe28:ab5e | ep1 |
| *E1 fec0:b200::/24 | V6E---R-- 0.0.0.0 | 101 0 | 192.168.10.1[4] | fe80::206:5bff:fe28:ab5e | ep1 |
4. Considerações Finais
O BGP4+ é o EGP aceito para o backbone IPv6 de teste - 6Bone (RFC 2772). Diversas regras para configuração de IGPs e EGPs devem ser seguidas para a estabilidade deste backbone. Este artigo apresentou alguns conceitos importantes sobre mudanças ocorridas nos protocolos de roteamento OSPF e BGP para suportar o protocolo IPv6.
Além disso, foram mostrados resultados práticos da utilização destes protocolos usando o software gratuito GNU Zebra em sistemas Linux e FreeBSD. Tais resultados tornam-se importantes para o entendimento das diferenças de configuração em relação ao IPv4, além de serem interessantes para uma futura conexão ao 6Bone brasileiro e mundial.
Referências bibliográficas
[1] CPqD. CPqD - Telecom & IT Solutions. Disponível em: <http://www.cpqd.com.br/>. Acesso em: julho 2002.HYPERLINK.
[2] RNP. RNP Projetos especiais: IPv6/BR6Bone. Disponível em <http://www.rnp.br/ipv6/>. Acesso em julho 2002.
[3] ISC. Internet Software Consortium. Disponível em <http://www.isc.org>. Acesso em julho 2002.
[4] SILVA, T. A. Piloto de Serviço IPv6: procedimento de configuração de DNS. NewsGeneration, v. 6, n. 3, 21 de maio de 2002. Disponível em: <http://www.rnp.br/newsgen/0205/ipv6_dns.html>. Acesso em julho 2002.
[5] CISCO. Cisco IOS Technologies - Cisco IOS IPv6. Disponível em: <http://www.cisco.com/warp/public/732/Tech/ipv6/>. Acesso em: julho 2002.HYPERLINK.
[6] COLTUN, R.; FERGUSON, S; MOY, J. OSPF for IPv6. RFC 2740, dez. 1999. Disponível em: <http://www.ietf.org/rfc/rfc2740.txt?number=2740>. Acesso em: julho 2002.
[7] CISCO. Cisco Connection Online by Cisco Systems, Inc. Disponível em: <http://www.cisco.com/>. Acesso em julho de 2002.HYPERLINK.
[8] ALBUQUERQUE, F. TCP/IP Internet Protocolos e Tecnologias. 2. ed. Ed. Axcel Book, 1999.
[9] COMER D. Interligação em Rede com TCP/IP. 3. ed. Ed. Campus, 1998.
[10] GNU Zebra. GNU Zebra - routing software. Disponível em: <http://www.zebra.org>. Acesso em julho 2002.
[11] MARQUES, P.; DUPONT, F. Use of BGP-4 Multiprotocol Extensions for IPv6 Inter-Domain Routing. RFC 2545, mar. 1999. Disponível em: <http://www.ietf.org/rfc/rfc2545.txt?number=2545>. Acesso em julho 2002.
[12] HALABI, S. Internet Routing Architectures. 2. ed. Cisco Press, ago. 2000.
[13] BATES, T. ; REKHTER, Y.; CHANDRA, R.; KATZ, D. Multiprotocol Extensions for BGP-4. RFC 2858, jun. 2000. Disponível em: http://www.ietf.org/rfc/rfc2858.txt?number=2858. Acesso em julho 2002.
NewsGeneration, um serviço oferecido pela RNP Rede Nacional de Ensino e Pesquisa
Copyright © RNP, 1997 2004