Edison Melo <melo@npd.ufsc.br>
Elvis Melo Vieira <elvis@npd.ufsc.br>
Solange T. Sari <solange@npd.ufsc.br>
Rede Metropolitana de Alta Velocidade de Florianópolis - RMAV-FLN
Resumo
Abstract
1. Introdução
2. Comportamentos dos Fluxos de Eventos Definidos
2.1 Start/Stop
2.2 Storm
2.3 Fluxo de Eventos Correlatos
2.4 Fluxo de Eventos Independente
3. Ações de Diagnóstico e Reativa à Ocorrência de um Evento
3.1 Procedimentos de Diagnóstico do Evento
3.2 Procedimento de Reação ao Evento
4. Prioridade dos Nós Gerenciados
5. Dicionário de Eventos
5.1 Atributos de Eventos
5.2 Procedimentos
6. Modelos de Tratamento de Eventos
6.1 Modelo Start/Stop
6.2 Modelo Storm
6.3 Modelo Correlato
6.4 Modelo Independente
7. Implementação de Correlações Para a MIB-II
7.1 Dicionário de Eventos
7.2 Implementação do Tratamento de Eventos
8. Utilização das Rulesets
9. Conclusão
10. Bibliografia
Resumo
Este trabalho descreve modelos de tratamento de eventos em uma rede IP com gerenciamento baseado em SNMP. Os modelos descritos são baseados no comportamento do fluxo de eventos que tratam e como exemplo de utilização, são ilustrados o tratamento de eventos utilizados no gerenciamento de objetos na MIB-II de um nó IP. Na implementação dos modelos e exemplos foi utilizado o Tivoli Netview como ferramenta suporte para o tratamento de eventos, mas os conceitos desenvolvidos podem ser aplicados em outras ferramentas.
Abstract
This paper describes event treatment models for a IP network with SNMP management. The described models are based on behavior of the event flow which they treat. As example, it is illustrated event treatment used for management of MIB-II objects of a IP node. All models and examples are implemented on Tivoli Netview which it is used as supporting tool to event treatment. However, the developed concepts can be used in other tools as well.
Palavras Chave
Tratamento de eventos, correlações, SNMP traps, Netview, rulesets, fluxo de eventos.
1. Introdução
O desenvolvimento de procedimentos para tratar fluxo de eventos[1] pode ser muito ineficiente se cada um for considerado isoladamente. Devido a grande quantidade de eventos presente em uma rede, este desenvolvimento pode se tornar um processo extenso e com poucos resultados.
Para tornar o tratamento de eventos em uma rede IP mais rápido e eficiente, foram estabelecidos modelos básicos. Para cada modelo, há um tipo de comportamento associado a um fluxo de eventos. Entretanto, todos os modelos de tratamento são dependentes da definição dos eventos. Para captar esta definição, definiu-se o dicionário de eventos, o qual serve como ponto de partida para a construção de uma rotina de tratamento de eventos a partir de um modelo básico.
2. Comportamentos dos Fluxos de Eventos Definidos
Através da análise dos tipos de eventos presentes em uma rede IP gerenciada através do SNMP [2][3], foram estabelecidos os seguintes tipos de comportamento de eventos: start/stop, storm, correlatos e independentes.
2.1 Start/Stop
Este comportamento é característico dos eventos que se apresentam aos pares. Um dos eventos indica quando uma certa condição se torna válida e o outro indica quando esta não é mais válida, a exemplo tem-se:
- Traps RMON - A MIB RMON-I[4] especifica os grupos Alarm e Event os quais pode ser utilizados para monitorar uma determinada variável SNMP no próprio agente RMON. Através do grupo Event podem ser definidos o evento start para anunciar que a variável ultrapassou certo limite e o evento stop, para anunciar que a variável retornou a um valor considerado normal.
- Traps SNMP de mudança de estados - Várias MIBs definem traps para anunciar mudanças de estados em variáveis SNMP. Por exemplo, os Links Down e Up [5][6] anunciam a disponibilidade de uma determinada interface.
- Eventos de Monitoração do Próprio Gerente SNMP - Em vários sistemas de gerenciamento (Netview, Openview, etc) podem ser estabelecidas monitoração remota de variáveis SNMP e associados eventos que anunciam que determinados limiares foram atingidos, tal como nos agentes RMON. Por exemplo, no NetView [7] [8], podem ser criadas coletas para monitorar uma determinada variável em um agente SNMP. Na coleta estabelecida podem ser associados dois eventos: um para anunciar quando a variável ultrapassou um limiar e outro quando a mesma variável retornou para um valor considerado normal.
Neste trabalho, apesar dos termos evento e trap tenham significados diferentes, não será feita distinção e os dois termos freqüentemente serão usados.
2.2 Storm
O comportamento deste fluxo de eventos se caracteriza pela ocorrência em seqüência, de vários eventos do mesmo tipo em um determinado período. Como exemplo, pode ser citado o trap Authentication Failure, o qual indica que um determinado agente SNMP recebeu uma mensagem com uma comunidade inválida.
Na maioria das vezes é mais interessante, neste tipo de fluxo, saber se um determinado limite de ocorrência de eventos foi atingido ao invés de tratar cada evento individualmente. No exemplo citado, um trap Authentication Failure talvez não seja tão significante. Tal ocorrência pode ser devido a um teste feito no gerente SNMP e não é interessante tratar tal evento. Entretanto, uma grande seqüência de tais eventos deve ser tratada, pois pode anunciar uma tentativa de quebra de segurança do sistema.
2.3 Fluxo de Eventos Correlatos
Dois eventos são correlatos, se a ocorrência de um evento estiver associada com a ocorrência do outro. Por exemplo, um trap Jabber pode ser gerado em um agente SNMP monitorando um interface Ethernet para anunciar a ocorrência de sinal de Jabbler na rede. Entretanto, logo em seguida um evento Link Down pode ser gerado pelo mesmo agente anunciando que a interface Ethernet foi desativada, provavelmente pelo mesmo motivo que ocorreu o trap Jabber. Portanto, correlacionando-se os dois eventos pode-se deduzir que a interface ethernet caiu pelo mesmo motivo que provocou o trap Jabber, provavelmente um problema em algum transceiver na rede.
2.4 Fluxo de Eventos Independente
Este tipo de fluxo se caracteriza pela ocorrência individual de um evento, o qual não tem uma relação significativa com outros eventos. Além disso, a ocorrência de um único evento já é importante e deve ser tratada. Um exemplo importante pode ser o trap PVC status change em links Frame-Relay.
3. Ações de Diagnóstico e Reativa à Ocorrência de um Evento
Foram detectados dois tipos procedimentos comuns contidos em todas as implementações dos modelos: procedimentos de diagnóstico e procedimentos que realiza uma reação ao evento.
3.1 Procedimentos de Diagnóstico do Evento
Um procedimento de diagnóstico é um conjunto de ações com o objetivo de auxiliar ou mesmo diagnosticar a causa que provocou o evento. Cada evento pode possuir um procedimento de diagnóstico particular ou utilizar o procedimento default.
O procedimento de diagnóstico default definido consiste em obter todos os valores das variáveis correlacionadas com o evento (e outras que ajudam a descrever o nó gerenciado) e armazená-las em um arquivo. Futuramente, o gerente da rede pode analisar este arquivo na tentativa de descobrir a causa do problema. Para os modelos propostos, foi escrito um script para obter todas as variáveis correlacionadas com um evento e armazená-las em um arquivo. Este script obtém da entrada padrão (no formato apresentado em Quadro 1 ) os nomes das variáveis a serem consultadas, escrevendo na saída padrão o valor obtido no nó gerenciado.
3.2 Procedimento de Reação ao Evento
Cada evento pode possuir um procedimento reativo que consiste em um conjunto de ações que procuram reagir a ocorrência de um evento. Exemplos deste procedimentos podem ser:
- Ativação de um link backup em reação à queda de um link.
- Aumento da largura de banda ou encerramento de um processo de um PVC ATM em reação ao aumento do tráfego.
- Alteração da rota default em reação ao excesso de pacotes IP não roteados.
- Envio de uma mensagem por pager ou e-mail para o gerente da rede.
- Envio de um evento para um sistema de help-desk.
O procedimento de reação default consiste no armazenamento de informações referentes ao evento e o envio de um e-mail para o gerente da rede.
4. Prioridade dos Nós Gerenciados
A priorização dos nós gerenciados visa informar para uma correlação qual a importância deste nó em relação aos demais. Dependendo da importância do nó referente em um evento, a forma como a correlação trata o evento muda. Por exemplo, para correlações que tratam eventos com o tipo de comportamento storm, o nível de prioridade influencia no tamanho do threshold do evento (número de eventos esperados em um certo período) como será visto adiante.
Para o tratamento de eventos, foram criadas duas coleções (conjuntos de nós gerenciados) no Netview para implementar priorização. A coleção AltaPrioridade que contém nós de alta prioridade e a coleção BaixaPrioridade que contém nós cuja prioridade é baixa, mas ainda assim maior que a prioridade normal. Quando o gerente de rede quiser indicar que um nó tem alta ou baixa prioridade, pode copiá-lo do submapa onde aparece para a coleção correspondente através da interface gráfica do NetView.
5. Dicionário de Eventos
Para auxiliar no desenvolvimento do tratamento de eventos, foi definido um dicionário de eventos. Um dicionário de eventos tem a finalidade de descrever os eventos, em termos de seus elementos ou características mais importantes, tais como comportamento, origem, prioridade do evento, procedimentos de diagnósticos e muitos outros atributos e procedimentos.
O dicionário de eventos é importante tendo em vista que este possibilita a documentação dos eventos gerenciados, incluindo aqueles implementados pela gerência da rede. Todos os eventos são descritos da mesma forma e são agrupados por tecnologia de rede envolvida como IP, Ethernet, Frame-Relay, ATM.
5.1 Atributos de Eventos
Um atributo de evento no dicionário indica uma característica de um evento, servindo para individualizá-lo em relação aos outros eventos do mesmo tipo. Cada evento no dicionário, possui os seguintes atributos:
- Tipo do Evento : é um string que identifica o tipo do evento em relação aos demais
- Enterprise ID : é um número que identifica a empresa responsável [2][3][5] pela definição do evento. Este número é cadastrado internacionalmente na Internet, sendo que cada Enterprise ID é único para cada empresa.
- Número Genérico do Trap (Generic Trap Number): tem o valor de 0 a 5 se for um trap com Enterprise ID 1.3.6.1.4.1 e 6 se for outro Enterprise ID [5].
- Número Específico do Trap (Specific Trap Number) : No caso de um trap com Número Genérico de 6, este número identifica o trap em relação aos outros de mesmo Enterprise ID [5].
- Comportamento : indica o modelo de comportamento do fluxo de eventos, os quais podem ser: start/stop, storm, correlato e independente.
- Endereço do Nó Gerenciado : é o endereço do nó gerenciado ao qual se refere o evento.
- Eventos Correlacionados : indica possíveis eventos que podem estar relacionados com o evento, se o comportamento da fluxo associado for correlato.
- Variáveis Correlacionadas : indica variáveis que podem estar correlacionadas com as causas da ocorrência do evento.
- Tempo de Ocorrência : o momento da ocorrência do evento.
- Origem do Evento: Programa que origina este evento, sendo possíveis dois valores: o agente SNMP remoto ou o próprio NetView através do seu sistema de coletas SNMP.
- Severidade : indica a severidade inicial do evento, a qual pode ser: Normal, Warning, Minor, Critical e Major.
5.2 Procedimentos
Cada evento no dicionário pode possuir dois procedimentos: um procedimento de diagnóstico e outro procedimento que realiza uma reação ao evento. No dicionário, os procedimentos são descritos através de comentários.
6. Modelos de Tratamento de Eventos
Cada modelo de comportamento de fluxo de eventos[9] corresponde um modelo de tratamento, o qual pode ser utilizado para implementar procedimentos de tratamento particulares a cada evento. Será utilizado o Netview como ferramenta de desenvolvimento, mais especificamente o editor de rulesets. No Netview, a implementação de um procedimento de tratamento de eventos é feita através da implementação de uma ruleset [7][8]. Entretanto, os princípios gerais se aplicam a qualquer outra ferramenta de tratamento de eventos.
6.1 Modelo Start/Stop
O modelo Start/Stop trata eventos que possuem comportamento start/stop. A Figura 1 ilustra este modelo utilizando a ruleset do Netview. Como pode ser visto, o fluxo de eventos passa por dois nodes Trap Settings, os quais filtram os eventos que compõem o par start e stop. Por exemplo, no caso de eventos Link Down (evento start) e Link Up (evento stop), o node Trap Settings de cima pode deixar passar somente o Link Down e o node Trap Settings de baixo, somente o evento Link Up.
Na seqüência do evento start, é verificado se este evento se refere ao nó gerenciado de alta ou baixa prioridade pelos nodes Query Collection. Para cada uma destas prioridades existe um procedimento de diagnóstico e um procedimento reativo representado pelos nodes Actions. Em seguida a severidade do evento pode ser alterada pelos nodes Override e o evento é enviado para a janela de eventos ou Workplace. No caso do NetView, é exibido de acordo com a nova severidade, indicada por uma cor adequada.
Na seqüência do stop, o evento é enviado diretamente para os nodes Pass on Match e Reset on Match. Neste dois nodes, o evento stop fica aguardando, por um determinado tempo (igual nos dois nodes), a chegada do evento start correspondente para o mesmo nó gerenciado e variável. Entretanto, os dois nodes tem comportamentos inversos. No node Pass on Match, o evento start somente passa adiante se o evento stop corresponde chegar antes do tempo determinado. Enquanto no Reset on Match, o evento stop (verificar que as entradas são trocadas) passa adiante somente se o evento stop não chegar no tempo determinado.
Se um evento start sair do node Pass on Match, este segue adiante para o node Resolve. No node Resolve, o evento start anteriormente enviado para ser exibido na Workplace é removido, uma fez que a causa do evento desapareceu.
Por fim, no node Reset on Match, se um evento stop escapa, este é exibido na Workplace, juntamente com o evento start anteriormente exibido. Desta forma, no Workplace somente aparecem os eventos Start/Stop cujo intervalo entre os dois é maior que um determinado tempo.
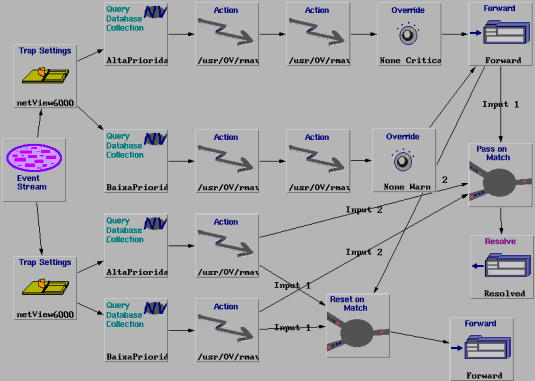
Figura 1 - Modelo de Correlação para o Comportamento Start/Stop
6.2 Modelo Storm
O modelo de correlação Storm trata eventos que possuem comportamento storm. A Figura 2 ilustra este modelo utilizando a ruleset do Netview. Nesta figura, o node Trap Settings filtra o evento desejado. Em seguida, o evento é passado pelos nodes Query Collection, o qual verifica a prioridade do nó gerenciado. Para cada uma destas prioridades existe um valor limite a quantidade de eventos suportada e o qual são verificados pelos nodes Threshold. Em seguida, os procedimentos de diagnóstico e representado pelos nodes Actions, são executados. Depois da execução destes procedimentos, a severidade do evento pode ser alterada pelos nodes Override e o evento é enviado para a janela de eventos ou Workplace. No caso do NetView, o qual é exibido de acordo com a nova severidade, indicada por uma cor adequada.
6.3 Modelo Correlato
O modelo Correlato trata fluxos de eventos correlacionados entre si. Este modelo é ilustrado pela figura Figura 3. Neste modelo, o evento principal deve ser filtrado pelo primeiro node Trap Settings. Os demais traps settings filtram os eventos correlacionados com o evento principal. Unicamente o evento principal provocará o acionamento dos procedimentos de diagnóstico e reativos (nodes Actions), classificado em termos da prioridade do nó gerenciado (nodes Query Collection), ter sua severidade alterada (nodes Override), e exibido no Workplace (node Forward). Os demais eventos são simplemente descartados pelo node Resolve.

Figura 2 Modelo de Correlação para o Comportamento Storm
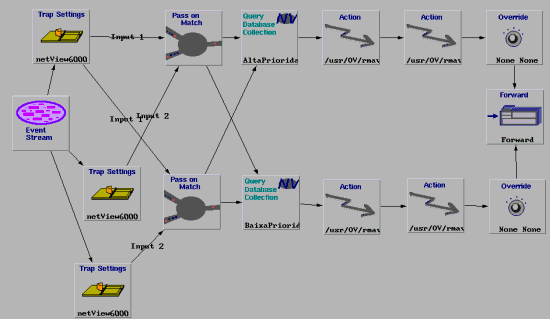
Figura 3 Modelo de Correlação para o Comportamento Correlato
6.4 Modelo Independente
O modelo de Indepente trata fluxo de um mesmo tipo de evento não correlacionados com outros tipos. Neste modelo (Figura 4), o evento é filtrado no node Trap Settings. Uma vez separado, o evento será classificado de acordo com a prioridade do nó gerenciável a que se refere o evento (nodes Query Collection) e seguirá um dos dois caminhos - de alta ou baixa prioridade - dependendo da classificação. Em qualquer um dos caminhos, o evento provocará o acionamento dos procedimentos de diagnóstico e reativo (nodes Actions), alteração de sua severidade (nodes Override) para ser exibido no Workplace (node Forward). Como nos casos anteriores, a nova severidade do evento e os procedimentos de diagnóstico e reativos são dependentes da prioridade atribuída ao nó gerenciado referente no evento.
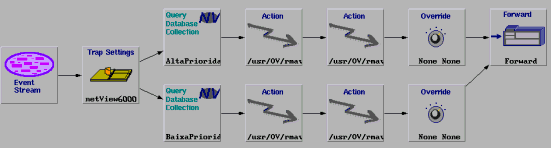
Figura 4 - Modelo de Correlação para o Comportamento Independente
7. Implementação de Correlações Para a MIB-II
Utilizando a estrutura proposta, um conjunto de correlações foi implementado para tratar eventos referentes às variáveis da MIB-II. Estes exemplos ilustram como podem ser utilizados o dicionário de eventos e os modelos de correlação para a implementação rápida de tratamento de eventos.
7.1 Dicionário de Eventos
Para tratar os eventos da MIB-II, será criado um novo grupo ou seção no dicionário de eventos chamado MIB-II. As entradas deste grupo utilizadas nos exemplos são:
- Evento Link Down : é o trap Link Down enviado por um agente SNMP.
- Evento RMAVFLN_ifInDiscards_Ris: evento configurado no NetView e indica que, durante a coleta feita em uma interface, esta atingiu um nível de descartes elevado.
- Evento RMAVFLN_ifInErrors_Ris: evento configurado no NetView e indica que, durante a coleta feita em uma interface, esta atingiu um nível de erros elevado.
- Evento RMAVFLN_tcpConn_Ris : evento configurado no NetView e indica que, durante a coleta feita no estado de um connexão TCP, esta ficou no estado closed. Este evento pode ser utilizado para monitorar a disponibilidade de um daemon TCP, por exemplo.
As entradas mostradas em Quadro 1, Quadro 2, Quadro 3 e Quadro 4 ilustram as especificações para os eventos Link Down, RMAFLN_ifInOctets e RMAFLN_ifInErrors.

Quadro 1 - Entrada no Dicionário de Dados para o Evento Link Down

Quadro 2 - Entrada no Dicionário de Dados para o Evento RMAVFLN_ifInOctets_Ris

Quadro 3 - Entrada no Dicionário de Dados para o Evento RMAVFLN_ifInErrors_Ris

Quadro 4 - Entrada no Dicionário de Dados para o Evento RMAVFLN_tcpConn_Ris
7.2 Implementação do Tratamento de Eventos
Com a ajuda do dicionário de eventos e dos modelos de tratamento, podem ser implementadas as rulesets do Netview ilustradas em Figura 5, Figura 6 e Figura 7.
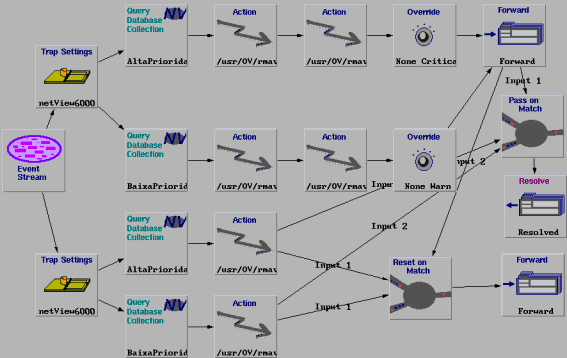
Figura 5 - Correlação para Tratar o Fluxo de Eventos Link Down e Link Up
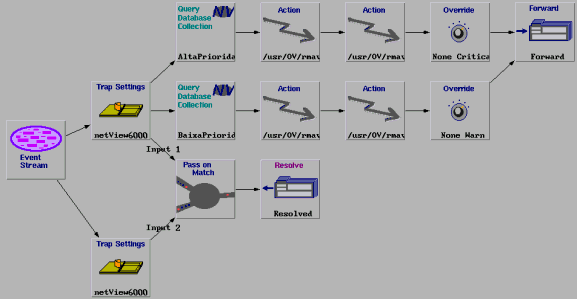
Figura 6 Correlação para Tratar o Fluxo de Eventos Evento RMAVFLN_ifInDiscards_Ris
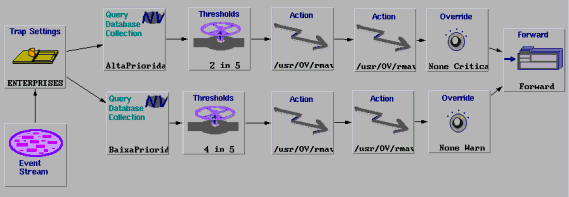
Figura 7 - Correlação para Tratar o Fluxo de Eventos Evento RMAVFLN_ifInErrors_Ris
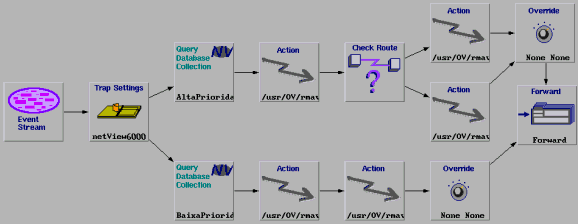
Figura 8 - Correlação para Tratar o Fluxo de Eventos Evento RMAVFLN_tcpConn_Ris
Quando aos procedimentos de diagnósticos, todas as rulesets utilizam o procedimento default, ou seja, é realizado um log do conteúdo das variáveis correlacionadas com o evento. Portanto, um arquivo de especificação das variáveis correlacionadas deve ser criado e informado em cada node Action para cada correlação. O nome destas variáveis podem ser obtidas no dicionário de dados. Nos Quadro 5, Quadro 6, Quadro 7 e Quadro 8 são ilustrados os arquivos resultantes para cada correlação.

Quadro 5 - Arquivo das Variáveis Correlacionadas para a Correlação Link Down/Link Up

Quadro 6 - Arquivo das Variáveis Correlacionadas para a Correlação RMAVFLN_ifInOctets

Quadro 7 -Arquivo das Variáveis Correlacionadas para a Correlação RMAVFLN_ifInErrors

Quadro 8 - Arquivo das Variáveis Correlacionadas para a Correlação RMAVFLN_ifInErrors
8. Utilização das Rulesets
Existem duas formas de utilização das rulesets. A primeira utilização visa criar uma janela de eventos particular ou uma Dynamic Workplace para a correlação. Através desta janela podem ser vistos todos os eventos que a correlação deixa passar, utilizando o node Forward. Está forma é indicada para um ambiente onde se tem um operador para vigiar a rede.
Outra forma de utilização é deixar a correlação executando em background, ou seja, independente da interface gráfica. Uma vez que o Netview é ativado, a ruleset já se torna ativa. Para isto, basta colocar o nome do arquivo da correlação no arquivo /usr/OV/conf/ESSE.automation. Entretanto, os nodes Forward devem ser retirados das rulesets, tendo em vista que a janela de eventos não será mais utilizada. Esta forma é indicada para a automação do tratamento de eventos, sem a necessidade da intervenção de um operador.
9. Conclusão
Através da utilização dos modelos de tratamento de eventos start/stop, storm, correlato e independente pode-se uniformizar o desenvolvimento do tratamento de eventos e torná-lo mais rápido. Além disso, com a utilização de um dicionário de eventos, este processo se torna também mais metódico, ou seja, um método, embora simples, para tratar eventos pode ser seguido. Pode-se notar que o bom projeto dos eventos passar a ter importância, o que implica em uma definição das variáveis a serem monitoradas (ou seja, quais coletas serão criadas), correlação de variáveis e eventos entre si e uma boa definição de quais traps SNMP serão tratados.
Por fim, pretende-se definir mais modelos de tratamento de eventos, inclusive composto através dos modelos básicos. No momento, o trabalho está sendo estendido para tratar eventos em redes ATM e Lan Emulation e no futuro novas tecnologias serão agregadas.
10. Bibliografia
[1] Cisco Networking and Event Correlation Guidelines - Reference Guide, Cisco Systems, 1999
[2] SNMP, SNMP V2 and CMIP, The Pratical Guide to Network Management Standards, Stallings, W.
[3] The Simple Book, Rose, T. M.,Ed. Prentice Hall, 1994
[4] RFC1757 - Remote Network Monitoring Management Information Base, Waldbusser, S., 1995.
[5] RFC1215 - A Convention for Defining Traps for use with the SNMP, Rose, T.,1991.
[6] Understanding SNMP Mibs, Perkins, D., McGinnis, E., New York, NY, Prentice Hall, 1997.
[7] TME10 NetView - Administrator's Guide Version 5, Tivoli Systems, SC31-8440-00, 1997.
[8] TME10 Netview, Tivoli Systems http://www.tivoli.com
[9] HP OpenView Event Correlation Services - Designer's Guide, J109-90304,1998.
NewsGeneration, um serviço oferecido pela RNP Rede Nacional de Ensino e Pesquisa
Copyright © RNP, 1997 2004